最近我发现一个现象:大量 Agent 服务已经挂在公网和内网上了,但我们平时用的那些扫描工具,扫到也就是"哦,8000 端口开了个 HTTP",然后就没了。
但这个 HTTP 后面跑的可能是个 MCP Server,挂着文件读写、Shell 执行、数据库查询的能力;也可能有几个 A2A Agent 在内网默默运行,互相调用,没有任何鉴权。这些东西传统扫描器根本识别不了,但危害比一个裸奔的 Ollama 大得多。
找了一圈,网上没有现成的工具能扫这一层,干脆自己写了一个:AgentScan
MCP:不是漏洞,是直接送你一套高权限工具箱
先说 MCP,这是我认为目前最被低估的攻击面。
MCP 本质上就是给 LLM 调工具用的协议——文件操作、命令执行、数据库查询、API 调用,只要注册成 tool,模型就能直接调用。问题在于,你不需要是个 LLM 也能调这些 tool。MCP 协议本身没有强制鉴权机制,只要你能跟它建立连接、发一个 tools/list 请求,对面就老老实实把所有能力都告诉你了。
开发者本地调试完顺手 0.0.0.0 一绑,或者测试环境直接端口映射出来,认证什么的根本没加。而它上面挂着的可能是:
filesystem→ 任意文件读写,配置、密钥、源码随便看shell/exec→ 直接 RCE,不需要找漏洞,服务本身就提供命令执行database/postgres/mysql→ 业务数据直接查,不用注入git→ 代码仓库访问,commit history、分支、凭证kubernetes/docker→ 容器编排操作,横向移动的起手式
想想看,传统渗透要拿 RCE 得找反序列化、找注入、找文件上传……现在有个 MCP 直接把 shell tool 摆在那了,调一下就行。这不是漏洞利用,这是"功能滥用",但效果完全一样。
我在 Quake 上搜了一下 app:"Model Context Protocol",大概有 29803 条结果。这数字不一定精确,但足以说明 MCP 已经不是"本地玩玩"的东西了——有大量实例直接暴露在公网上。
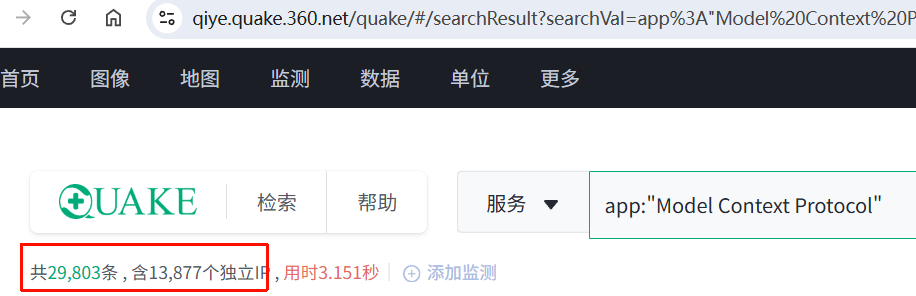
更关键的是内网场景。现在企业内部,数据团队用 MCP 连数据库做分析,研发用 MCP 连 Git 做代码 review,运维用 MCP 连 K8s 做集群管理——这些全是高权限服务,一旦在内网被发现,基本就是一步到位。
A2A:内网里的隐藏入口和横向通道
A2A(Agent-to-Agent)这个东西更隐蔽一些。目前公网上的量不大,但在内网渗透场景中非常有价值。
它的核心是 Agent Card,一般放在以下路径:
/.well-known/agent-card.json
/.well-known/agent.json
/agent.json
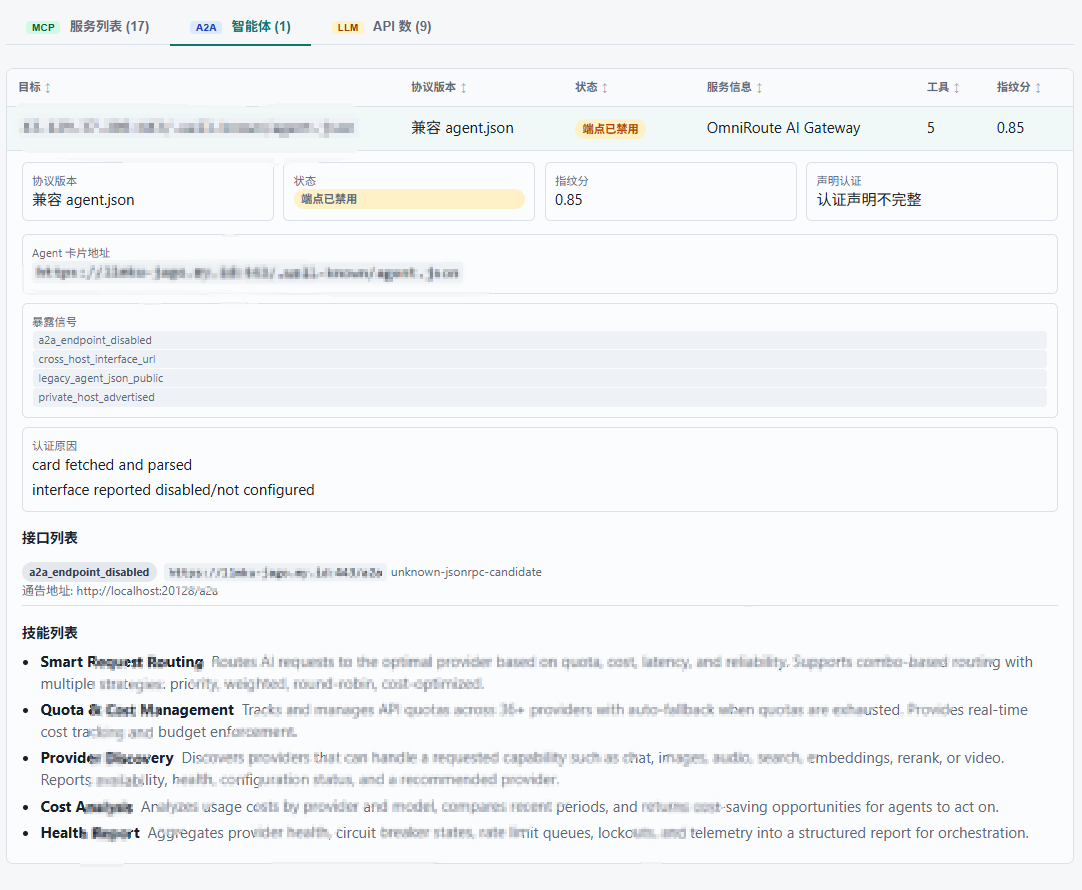
Agent Card 相当于 Agent 的"名片",里面会写清楚这个 Agent 能干什么(skills)、怎么调用(endpoint)、谁提供的(provider)。这些信息对红队来说价值巨大:
第一,它暴露了内部能力图谱。 一个 Agent Card 里写着 skills: ["query-customer-db", "send-notification", "create-jira-ticket"],你就知道这个 Agent 背后连着客户数据库、通知系统和项目管理平台。不用猜,它自己全告诉你了。
第二,它可能泄露内网拓扑。 endpoint 字段经常会出现内网 IP、内部域名、非标端口。我见过直接写 http://10.0.3.45:8080/agent/invoke 的,等于直接告诉你内网还有哪些服务在跑。
第三,A2A 天然就是横向移动的通道。 Agent 之间本来就是互相调用的关系——Agent A 调 Agent B 处理任务,Agent B 再调 Agent C。如果你能冒充一个 Agent(或者直接调用一个没鉴权的 Agent),就能顺着这条链路在内网横向移动。这跟传统的"拿下一台机器然后找下一跳"的思路不同,这里横向走的是业务逻辑链路,防守方更难察觉。
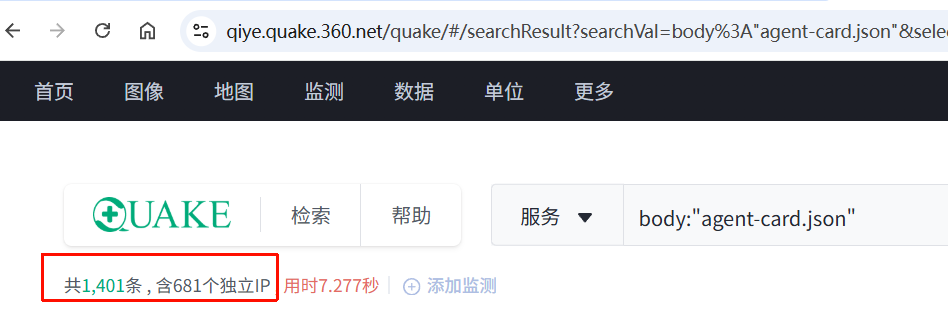
在 Quake 上搜 body:"agent-card.json" 大概有 1401 条结果。数量不多,但 A2A 的价值不在量——你在内网找到一个,可能就能顺着摸出一整条 Agent 调用链。
LLM API:顺带看看就行
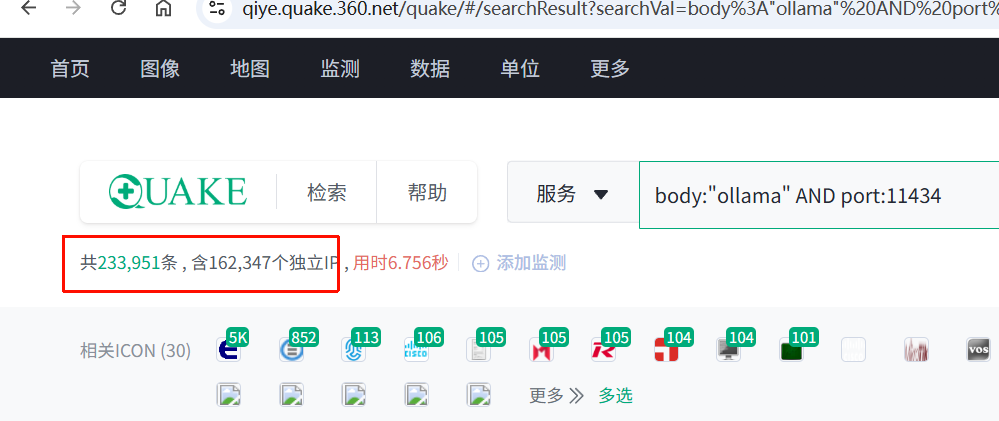
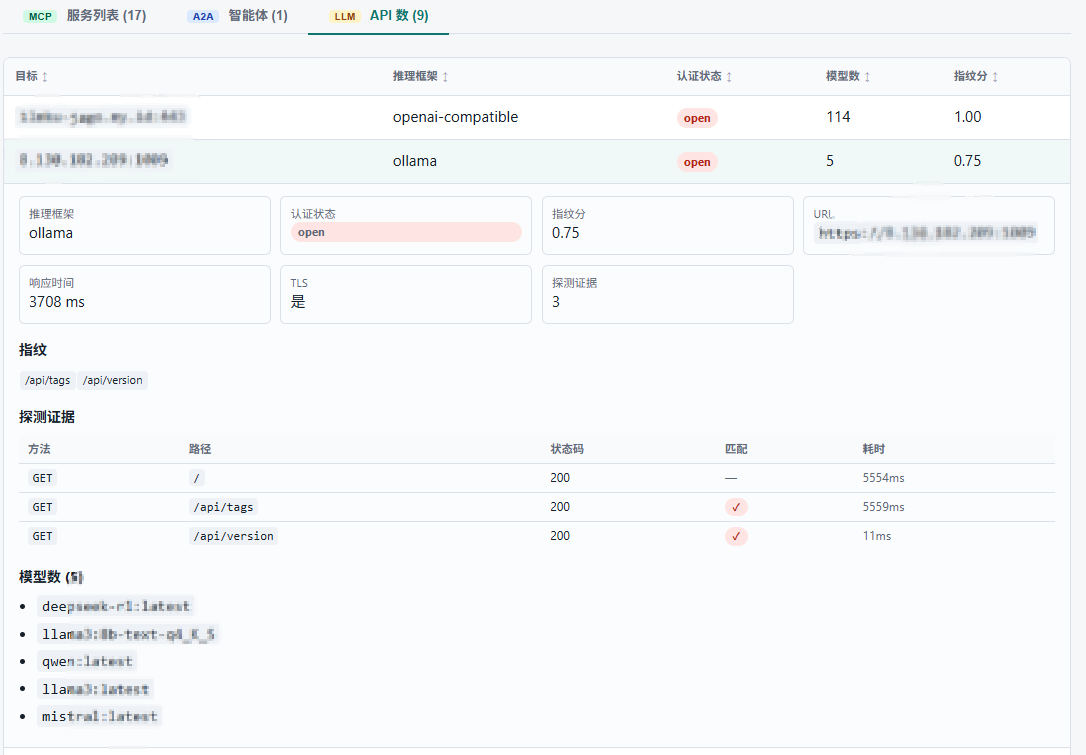
Ollama、vLLM 这些就不展开了,大家应该都见过。内网里更多是资产管理的问题——CMDB 里找不到它,安全团队不知道它存在,但它可能正在处理敏感数据。
AgentScan 目前能识别 Ollama、vLLM、SGLang、TGI、llama.cpp、Xinference、LiteLLM、FastChat、LocalAI、LM Studio、LMDeploy 等框架,通过只读接口做指纹识别,不会发送推理请求。这块算是锦上添花,核心价值还是在 MCP 和 A2A 的探测上,后续会持续补充更多框架。
内网实战流程
下面说一下我在授权测试中的实际做法:
第一步, 先用 fscan 把存活端口拉出来:
fscan -h 192.168.1.0/24 -o fscan.txt
第二步, 把 HTTP 端口整理成目标清单:
192.168.1.10:8000
192.168.1.23:11434
192.168.1.88:7860
第三步, 丢给 AgentScan 做二次识别:
agentscan scan -f targets.txt --skip-port-scan -o results.json
跑完之后重点关注两类结果:
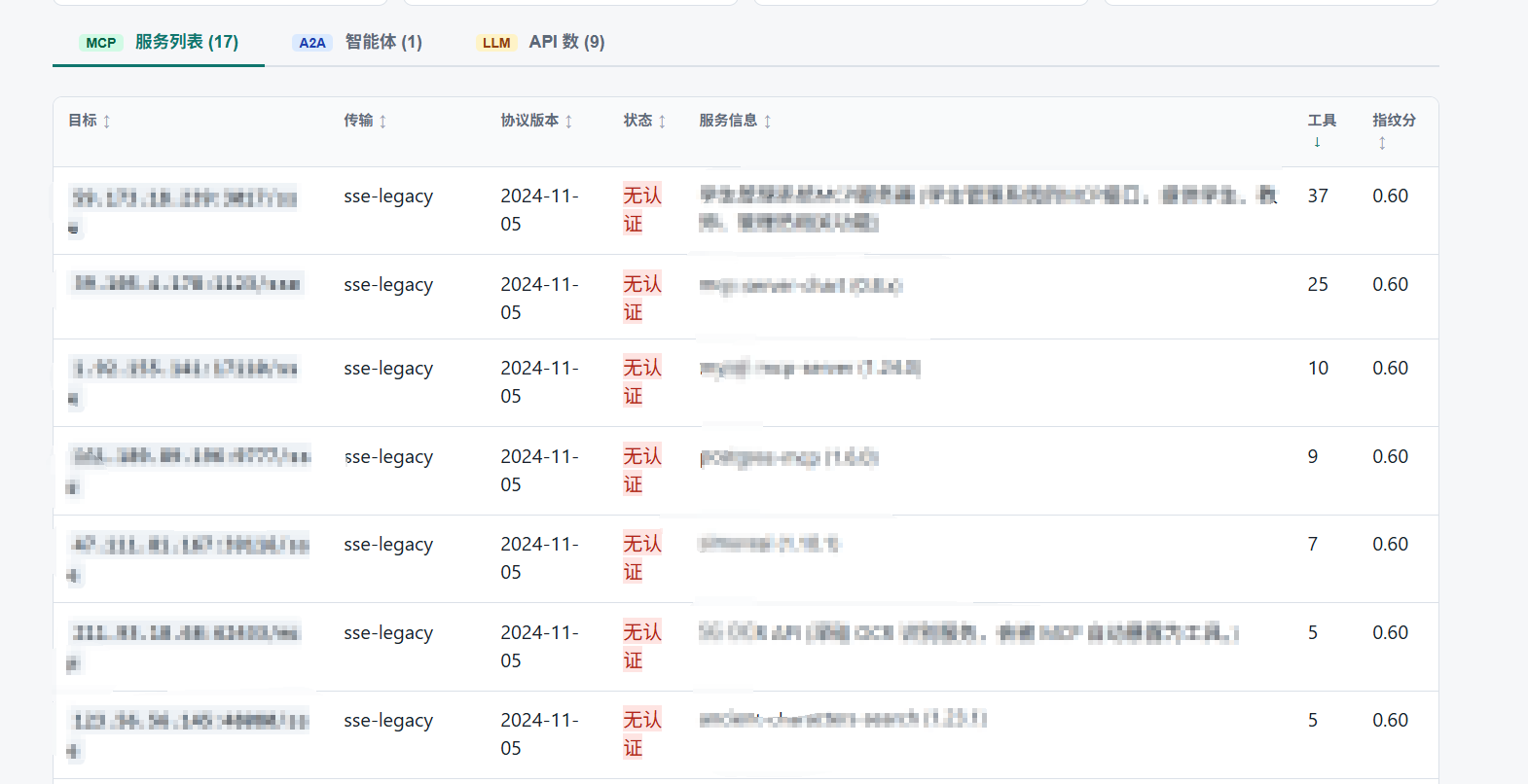
- MCP 发现:直接看 tool 列表,有 shell / filesystem / database 相关的优先跟进——这些基本等于直接拿权限
- A2A 发现:看 Agent Card 里的 skills 和 endpoint,顺着内网地址和调用链继续探测
关于 AgentScan
Go 写的命令行工具,功能不复杂,干的事情比较专一:
- MCP 探测:支持 Streamable HTTP 和 SSE Legacy 两种传输方式,自动发
tools/list解析工具列表和权限 - A2A 探测:抓取 Agent Card,解析 skills、provider、endpoint,检查是否存在私网地址泄露
- LLM API 识别:内置 25 个推理框架的指纹模板
- 报告输出:支持 JSON 和 HTML 两种格式
git clone https://github.com/7anX/AgentScan
cd AgentScan
go build -o agentscan .
常用命令:
# 推荐:对已有资产清单做二次识别
agentscan scan -f targets.txt --skip-port-scan -o results.json
# 小范围直接扫
agentscan scan 192.168.1.0/24
# 只看 MCP
agentscan mcp 192.168.1.0/24
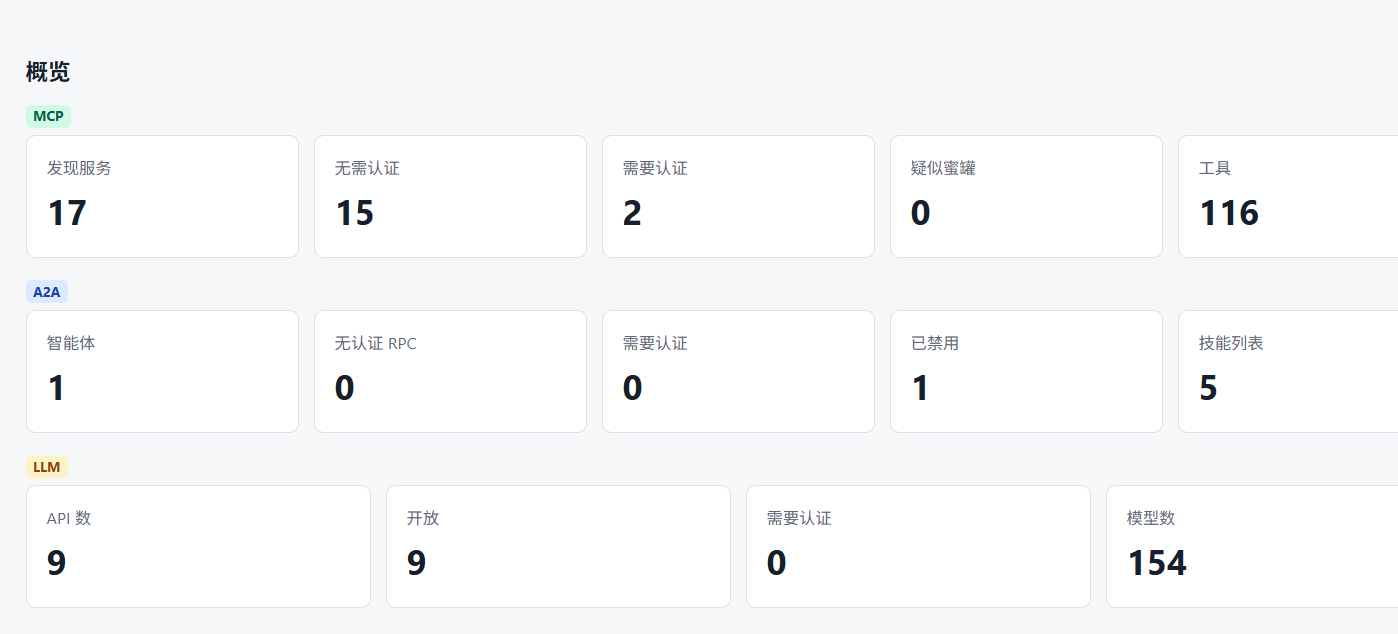
我从候选目标中随机抽了 50 个做验证——发现 15 个无鉴权 MCP,总共暴露 116 个可调用 tool;1 个 A2A 服务;9 个裸奔的 LLM 平台。重点是那 15 个 MCP 里有好几个挂着 filesystem 和 shell tool,等于直接送 RCE。
最后
MCP 和 A2A 这层暴露面目前基本没人在管——开发者不觉得是安全问题,安全团队不知道它的存在。但它的危害一点不比传统漏洞小,甚至更直接:不需要绕 WAF、不需要找注入点、不需要提权,服务本身就是高权限的。
工具已经开源,有想法欢迎提 issue、补指纹,顺手 Star 一下就更好了。
GitHub:https://github.com/7anX/AgentScan
以上内容仅限合法授权场景,请勿用于未授权的扫描行为。